- Code
- 1. Goal
- 2. Environment
- 3. Approach
- 4. Experiment & Findings
- 5. Next Steps
Code
1. Goal
The motivation of this project is AlphaGo and its mechanism of self-play. So I took on the task of implementing a very simple self-play mechanism that is able to train 2 agents in mastering tic-tac-toe with only the visible state/reward information. No information on the rules of the game or prior knowledge.
The goal of this project is two folds:
- Train a reinforcement learning agent to beat the predefined min-max agent, this is a good starting point for self-play because it would be very inefficient to train two dummy agents to learn from scratch.
- Using the trained agent from step (1), self-play against a copy of itself. Obviously one will go first. We expect that given the mechanics of tic-tac-toe, the two agents will converge to a draw game every single time.
2. Environment
The environment contains a mini-max tic-tac-toe player. This is used as a starting point for training the reinforcement learning agent.
State
The states are stored in a 3x3 grid.

Action
‘X’ - denotes the first player
‘O’ - denotes the second player
Reward
This wasn’t part of the original environment. This was intentionally left as a open-ended discussion which will be covered in section [3.1 Reward Design] since this will determine how well the agent can learn.
Termination Condition
The game (episode) is terminated when either player wins or the game is drawed by having all the board cells filled with actions.
3. Approach
3.1 Reward Function Design
Assumption: This reward design is assuming the agent always goes first in the game. This will change in the self-play setting, which is covered in [4.2 Optimal Policy Discussion]
The reward function is designed as follows:
- if agent wins: +20
- if agent loses: 0
- if agent ties: +10
- For every step the agent makes: -2
The design of the rewards is closely related to how the game can terminate, specifically:
- Tie when the board is fully occupied (9 pieces)
- Win as early as 3 moves in, or as late as 5 moves in (full board)
- Lose is symmetric to win
The design is also dependent on the priority of the strategy, specifically:
- Priority 1: Win
- Priority 2: Tie
The reason for having a small negative reward at every step is because the Tic-Tac-Toe game’s environment is set in a small 3 x 3 board, and even for a very smart agent, the later the game proceeds to, there are less moves for the agent to win. Even with a smart agent, the game will more likely result in a tie in a late game battle. Therefore, the negative reward at each step is to encourage the agent to finish the game as early as possible, which, in turn, increases its probability of winning the game.
The reward values for the win condition should be high enough to encourage good actions. The tie reward is the mid-point for win and lose, but also taking into account, if a game is played until the board is fully occupied (9 pieces), the sum of rewards for winning that late game should be the same as a tie. Since the agent always goes first, it can, at most, have 5 moves before the no moves left, this translates to \(-2 * 5 + 20 = 10\) episode reward. As mentioned before, we want to encourage the agent to win the game as early as possible. Therefore, winning a late-game is considered the same as tie, from a rewards perspective.
3.2 Learning Algorithm
I chose to use Q-learning to solve this problem. This specific TIC-TAC-TOE game has a small fixed game board of \(3 \times 3\). Specifically, there are, at most, \(3^9 = 19683\) possible game states, in which there are 3 possible states (empty, X or O) for each of the \(3 \times 3 = 9\) positions. This can easily fit into the computer memory. Therefore, within a reasonable amount of training time, Q-learning is expected to find the global optimal policy. The discussion on how to determine whether the policy is a global optimal policy is in [4.2 Optimal Policy Discussion].
The q-table is represented as a HashTable, specifically: {"hashed_state": q-value}. The hashed_state is just the game board converted into a string (i.e. 000000000).
3.3 Hyperparameters
- Learning Rate (\(\alpha\)): 0.1
- Exploration Rate (\(\epsilon\)): Initially 1, decreasing linearly with respect to episodes to 0
- Discount Rate (\(\gamma\)): 0.9
4. Experiment & Findings
4.1 Training Evaluation
The reward in the plot is the sum of rewards for every episode averaged over the last 20 episodes to reduce noise in the plot.
Evaluating Trained Policy
EP100 | Agent Reward: -4
EP200 | Agent Reward: -4
EP300 | Agent Reward: 16
EP400 | Agent Reward: -6
EP500 | Agent Reward: 16
EP600 | Agent Reward: 14
EP700 | Agent Reward: 16
EP800 | Agent Reward: 16
EP900 | Agent Reward: 16
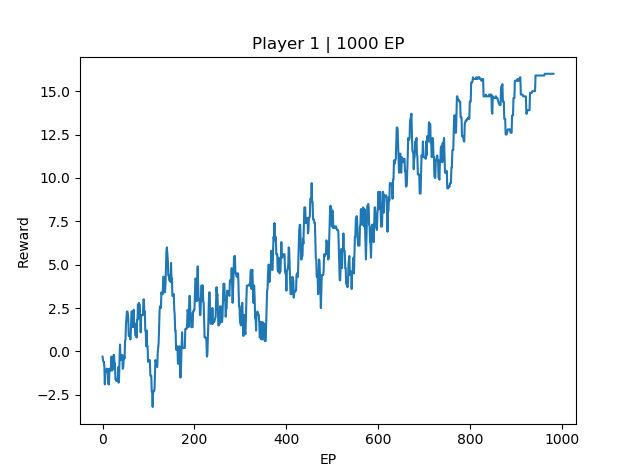
EP1000 | Agent Reward: 16
EP[1000] Avg Reard: 16.0
EP100 | Agent Reward: -4
EP200 | Agent Reward: 16
EP300 | Agent Reward: 16
EP400 | Agent Reward: 16
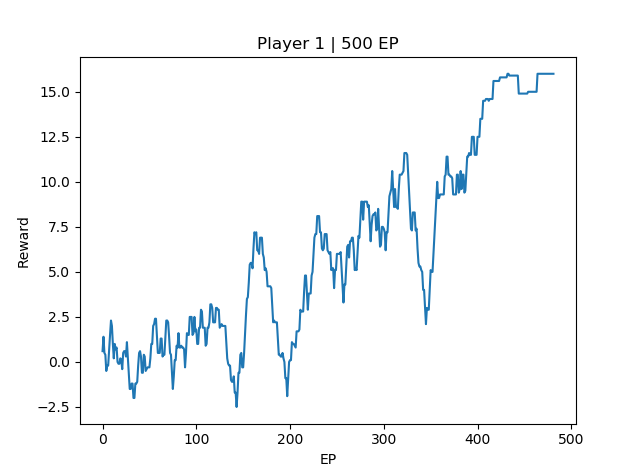
EP500 | Agent Reward: 16
EP[500] Avg Reward: 14.9
EP100 | Agent Reward: -6
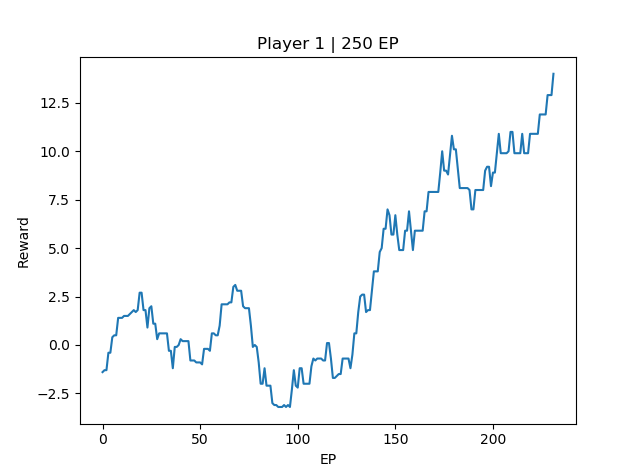
EP200 | Agent Reward: 16
EP[250] Avg Reward: 14.0
Discussion
From the three training instances, We can see that the 1000 EP agent, at the end of training, the final reward is above +10, and the test run shows 100% win rate against the opponent. However, there is still room for improvement for both the 250EP agent and 500EP agent compared to the 1000EP agent. Intuitively, this difference maybe due to the agent not able to win the game early on, resulting in a late game tie. The final reward for 1000EP agent is around 16, which is equivalent to winning the game in 3 steps (\(-2 * 2 + 20 * 1\)). The other two 500EP and 250EP agents only manages to reach around 14.9 and 14 episode reward respectively, which is probably converging to a local optimal of tie more than the win state.
4.2 Optimal Policy Discussion
A more direct way to determine whether the agent has learnt the globally optimal policy is to play the agent against itself. If the agent indeed learn the optimal policy, then both agents should reach a 100% tie rate.
Notation: The agent that goes first will be denoted as Player 1 and the agent that goes second will be denoted as Player 2.
Experiment - Play two copies of the same agent against each other, by following the trained policy
By following a trained optimal deterministic strategy, after playing the trained agent against a copy of itself, Player 1 always wins. This is because the policy is trained on going first, and will not perform well if used by Player 2.
Experiment - Train two agents against each other (self-play)
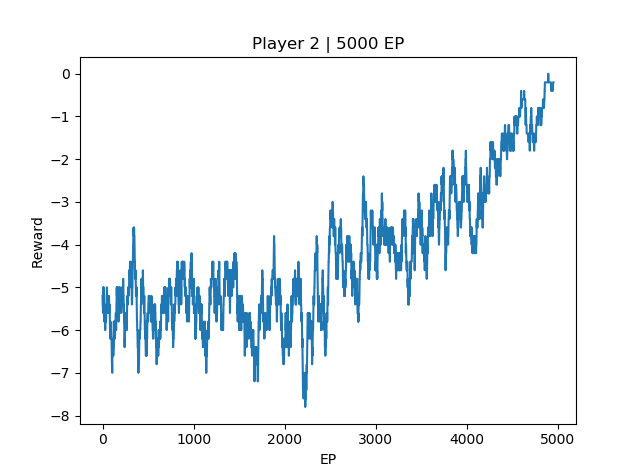
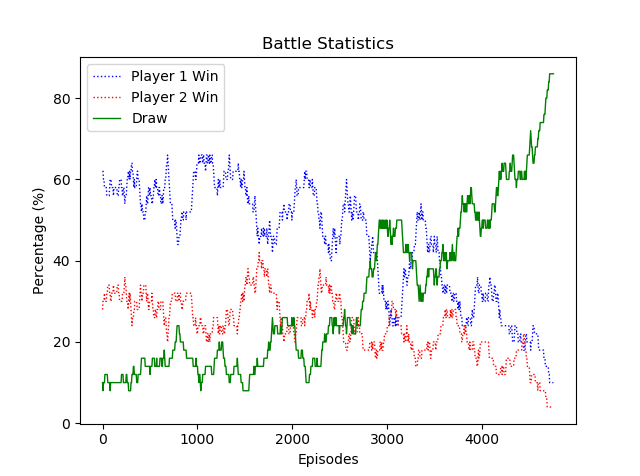
Note that I modified the reward structure for self-play. Win: +10, lose: -10, draw: 0, step: 0. The reward in the plot is the sum of rewards for every episode averaged over a moving 50 episodes to reduce noise in the plot. Based on the reward plot below, the 2 agents successfully converge to 0 reward and 100% tie rate. To verify that this is indeed a global optimal policy, refer to my next experiment, which runs the self-played agent against the original min-max agent.
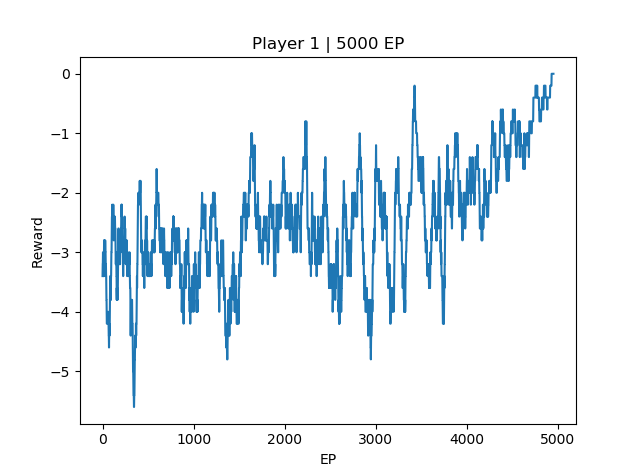
Experiment: Re-evaluate how a self-play agent (Player 1) performs against min-max opponent
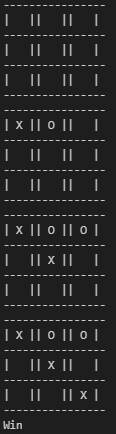
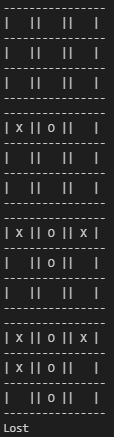
We would expect the self-played agents to converge to the global optimal policy, but it could be because the two agents are ‘colluding’ with each other and reaching the ‘tie’ state as the best outcome, similar to the prisoner’s dilemma. To verify this, we have to re-evaluate the self-played agent (Player 1) against the min-max opponent again to see. To verify my point, I intentionally ran two versions of self-play, (1) \(\textit{With}\) pre-trained policy that was trained against the min-max agent first, then self-play. (2) \(\textit{Without}\) pre-trained policy, the two agents self-play from scratch. Below are the outcomes after evaluating against the min-max opponent again. We can see that without prior knowledge, the self-play agent lost to the min-max agent. However, with prior training, the self-play agent won the min-max agent, thus verifying that it indeed reached the global optimal policy.
Effects of Prior Training
5. Next Steps
Since this is a static game, we could extend this agent to play a more generic version of tic-tac-toe, with either a larger board size or with different mechanics (connecting more than 3 lines to win).
Since the reward function is defined in a very flexible way. There are potential opportunities to change the reward design to see if it has effects on the learning speed and agent performance.
This is the first step towards AlphaGo. There are way more complexities when it comes to mastering such a complicated game. But this is a taste of the capability of self-play in reinforcement learning.