- 1. Motivation
- 2. Goals
- 3. Starting Point
- 3. Related Work
- 4. Project Focus/Scope
- 5. Showcase
- 6. Supervised Learning
- 7. Challenges
- 8. Statistics and Performance
- 9. Error Analysis + Future Steps
Brawlstars: https://supercell.com/en/games/brawlstars/
1. Motivation
I’ve personally being playing Brawlstars for over 3 months, and it’s a simple game to start considering the limited key combinations that it has. However, it’s fairly hard to master, considering the different mechanics each character has and the different maps in which each character’s play style can be affected by.
2. Goals
For this project, I want to train an agent that will be able to play Brawlstars decently (be able to consistently beat built-in AI, and be able to play in Player-vs-Player (PVP) games “like” a human player. During the process, my personal goal is to brush up on topics in computer vision and deep learning.
3. Starting Point
As for the game, I will start with the “Bounty” game mode and the “Temple Ruins” map as the fixed map, with “Shelly” being the character to train on.
Map

Character
More info: https://brawlstars.fandom.com/wiki/Shelly

Game Mode
Bounty: https://brawlstars.fandom.com/wiki/Bounty
Considerations
-
Ultimately, I will want to explore Reinforcement learning (RL), and one of the hardest things is reward definition. (Refer to my post about defining reward in stock trading using RL). The “Bounty” game mode allows for straight-forward reward definition by the number of stars each player gains by killing the opposing players.
-
“Shelly” has a simple set of attack mechanics. Her normal attack is short-to-medium range, and her super attack is the same range with more damage.
-
Using a fixed map allows me to eliminate a lot of the variation in agent performance due to map mechanics or other factors that is derived from the map.
3. Related Work
FIFA AI For inspiring me to try out LSTM for action determination in supervised learning.
PyGTA5 For the initial direction with regards to perception and supervised learning training data generation.
4. Project Focus/Scope
In the first part of this series of projects, I will be exploring the possibility of using supervised learning to train an agent to play Brawlstars. In the process, I will evaluate different feature extractors and identify other areas of improvements.
The second part of the project is to use reinforcement learning to let the agent play Brawlstars on its own and learn from it’s own mistakes. In this process, I will evaluate various RL techniques to improvement the agent’s decision-making abilities.
5. Showcase
6. Supervised Learning
6.1 Creating training data
As the name suggests, supervised learning requires training data with labeled ground truth. As for this project, I will be the person creating the training data by playing the game. The screen information and my key presses will be recorded into training data, which will be fed into the agent during the training process.
6.2 Features
6.2.1 Raw Pixels as Features
Feeding in raw pixels doesn’t yield too good of a result, because it’s difficult to make sense of individual pixels and translate them into concrete meaning. For example, it’s hard for the agent to infer from raw pixels which set of pixels corresponds to the its own player, allies or enemies.
For my training instance, I used 1 hour of game play data played only on the fixed map “Temple Ruins”.
6.2.2 Using MobileNet as the feature extractor
After seeing the performance of raw pixels, I decided to try out some feature extractors that could help with the performance of the agent for Supervised Learning. I chose Mobilenet as the feature extractor for its balance between high accuracy and fast speed.
For my training instance, I used 1 hour of data played only on the fixed map “Temple Ruins”.
6.3 Action Determination
6.3.1 AlexNet (Convolutional Neural Network)
Motivation: As a starting point, AlexNet is fairly robust for image feature extraction and classification.
Input: Raw Pixels
Output: A one-hot array of 6 elements. Representing (left, right, forward, backward, attack, superattack) Basically, the neural network will try to classify “snapshot” of the game screen into one of 6 actions.
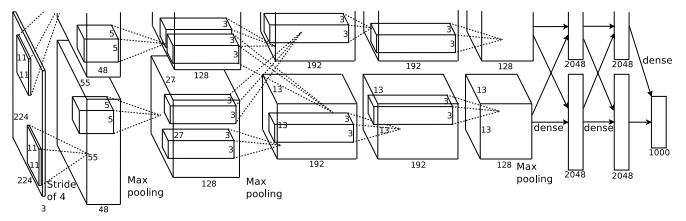
Paper Reference: https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
6.3.2 Long short-term memory
Motivation: Because this is a game with animation composed of frames of game screen. It is intuitive to think that a sequence of frames will provide more information than one snapshot of the game screen. This is the main motivation for choosing LSTM. The intuition behind separating into 2 LSTMs is because the movement actions and attack actions are not necessarily mutually exclusive—one can, and ought to, move and attack at the same time.
Input: Features extracted by MobileNet from after the last convolutional layer and right before the softmax.
Output: A one-hot array representing the actions to take
LSTM1 - A one-hot array of 5 elements. Representing (left, right, forward, backward, no-op)
LSTM2 - A one-hot array of 3 elements. Representing (attack, superattack, no-op)
Note that each set of actions includes no-op (no action) compared to the AlexNet approach.
Input - LSTM Layer 1 - Dropout - LSTM Layer 2 - Dropout
- Fully Connected Layer - Softmax Activation
Training blew up my home desktop due to the amount of memory the feature space occupys at the peak. I had to use Google Cloud’s VM with 32GB of ram to train this.
7. Challenges
7.1 Data
The challenge with supervised learning is always with data gathering. In this case, I can’t gather a huge amount of gameplay data for the agent to be trained to play well. Also, the generalization ability of supervised learning is questionable. Does the agent play well on other maps? Other characters? I believe incorporating reinforcement learning into the equation will allow the agent to develop a more robust and general strategy for playing this game. Also, by using RL, I personally wouldn’t need to “waste time” playing the game to generate training data.
7.2 Features
Since there was no game “hacking” involved or game data available for the agent to use, getting the features to be passed into the agent for supervised learning was challenging. I had to visualize the CNN intermediary layers to understand if the CNN was useful in detecting and classifying elements of the game. This was important because even if the agent’s decision-making abilities (planning) were superb, giving misleading information (bad perception) might still lead to chaos.
Snapshot of Intermediate CNN Layers
This is visualized using the second-last (CONV-5-1) block (out of 5 blocks) of the Very Deep Convolutional Networks for Large-Scale Image Recognition (VGG) architecture.
 Reference: https://neurohive.io/en/popular-networks/vgg16/
Reference: https://neurohive.io/en/popular-networks/vgg16/

8. Statistics and Performance
The input screen dimension: 1280 x 715 (cut off some pixels from the title bar)
Supervised Learning
- Trained on Raw Pixels fed into Alexnet for decision output with the following hyperparameters:
- EPOCHS=500
- Learning Rate=\(3e^{-5}\)
- Resize_Width=80
- Resize_Height=60
- Batch size=12
- Trained on MobileNet extracted features fed into 2 LSTMs for decision output with the following hyperparameters:
- Mobilenet
- Learning Rate=\(3 \times 10 ^{-5}\)
- Batch size=8
The best way to evaluate performance in this game is by keeping track of the average number of stars the player possess throughout the game. This is a high-level reward/goal because it encompasses short-term goals of killing the oponent and gaining an additional star each time and a long-term goal of not dying and resetting the player’s stars to 2.
Human Benchmark (Measured by myself): For the given setting, I can, on average, possess 5 stars throughout the game. With aggresive playstyle taking the initial 30 seconds, and conservative playstyle dominating the last 30 seconds, to preserve the 7 max stars on the player.
Agent Performance: For the given setting, in the supervised learning approach, the results weren’t impressive. The agent does avoid running into the wall, but attacks randomly at no target.
9. Error Analysis + Future Steps
I wasn’t surprised that supervised learning in a dynamic multi-agent environment would not go well. Unless I have near infinite amount of training data, I wouldn’t be able to train a decent agent.
Next, I will attempt to tackle this problem from a more fundamental level, starting from perception. Currently, I simply “dump” the pixels as input to a feature extractor, and hope that it will be able to transfer-learn some useful features.
Then, I am going to apply reinforcement learning on this problem to tackle the planning part of it. I will be framing the environment, constructing the agent’s brain, and designing rewards.
If you’re interested, please check my next post here. Thanks!
- Henry